SQLyog如何创建数据库,详细教程,SQLyog如何创建数据库,你知道怎么操作吗?下面将详细介绍......
Mysql技术内幕——表&索引算法和锁
来源:互联网
2023-03-16 23:01:44 版权归原作者所有,如有侵权,请联系我们
表
4.1、innodb存储引擎表类型
innodb表类似oracle的IOT表(索引聚集表-indexorganized table),在innodb表中每张表都会有一个主键,如果在创建表时没有显示的定义主键则innodb如按照如下方式选择或者创建主键。首先表中是否有唯一非空索引(unique not null),如果有则该列即为主键。不符合上述条件,innodb存储引擎会自动创建一个6字节大小的指针,rowid()。
4.2、innodb逻辑存储结构
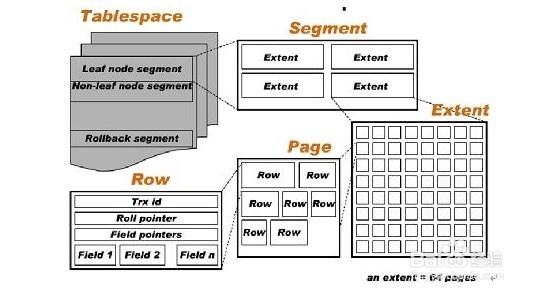
innodb的逻辑存储单元由大到小分别是 tablespace,segment,extent,page(block)组成
4.2.1、表空间(tablespace)
所有数据都是存放在表空间中的,启用了参数innodb_file_per_table,则每张表内的数据可以单独放到一个表空间中,每张表空间内存放的只是数据,索引和插入缓冲,其他类的数据,如undo信息,系统事务信息,二次写缓冲等还是存放在原来你的共享表空间。
4.2.2、段(segment)
常见的segment有数据段、索引段、回滚段。innodb是索引聚集表,所以数据就是索引,索引就是数据,那么数据段即是B 树的页节点(leaf node segment),索引段即为B 树的非索引节点(non-leaf node segment)。而且段的管理是由引擎本身完成的。
4.2.3、区(extend)
区是由64个连续的页主成,每个页大小为16K,即每个区的大小为(64*16K)=1MB,对于大的数据段,mysql每次最多可以申请4个区,以此保证数据的顺序性能。
4.2.4、页(page)
页是innodb磁盘管理最小的单位,innodb每个页的大小是16K,且不可更改。常见的类型有:数据页 B-tree Node;undo页 Undo Log Page;系统页 System Page;事务数据页 Transaction system Page;插入缓冲位图页 Insert Buffer Bitmap;插入缓冲空闲列表页 Insert Buffer freeBitmap;未压缩的二进制大对象页Uncompressed BLOB Page;压缩的二进制大对象页 Compressed BLOB Page。
4.2.5、行
innodb存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存放。每个页最多可以存放16K/2~200行,也就是7992个行。
4.3、innodb物理存储结构
innodb引擎由共享表空间,日志文件(redo log),表结构定义文件组成。
4.4、innodb行记录格式
mysql从5.1开始,innodb提供了compact和redundant(为了兼容以前版本)两种格式来存放行记录数据。
4.4.1、compact行记录格式
Compact行记录的设计目标是能高效存放数据。不管是char还是varchar类型,NULL指是不占用存储空间的。行记录中还包括两个隐藏列 事务ID列(6字节)和回滚指针列(7字节) 若没有定义的PrimaryKey 会增加一个6字节的RowID列。InnoDB在页内部是通过一种链表方式串联各个行记录的。
4.4.2、redundant行记录格式
Redundant行记录格式为了兼容以前版本。每个行最多有1023个列,因为列的数量占用了10位。对于varchar的NULL值,它不占用任何存储空间,而对于类型char的NULL值需要占用空间。
4.4.3、行溢出数据
innoDB存储引擎可以将一条记录中的某些数据存储在真正的数据页面之外,作为行溢出数据。Varchar(N)中的N指的是字符的长度,官方手册中定义的65535长度是指所有VARCHAR列的长度总合。
数据一般都是存放在B-tree Node的页类型中,但是发生行溢出的时,存放行溢出的页类型为Uncompress BLOB Page。如果一个页中至少放入两行的数据,那varchar就不会存放到BLOB页中,阀值长度为8098。对于TEXT或者BLOB的数据类型,我们总是以为它们是放在Uncompressed BLOB Page中的,其实这也是不准确的,放在数据页还是BLOB页同样和前面讨论的VARCHAR一样。
4.4.4、compressed与dynamic记录格式
InnoDB Plugin引入了新的文件格式成为Barracuda文件格式,它拥有两种新的行记录格式Compressed和Dynamic两种,它对于存放BLOB的数据采用了安全的行溢出方式。
4.4.5、char的行结构存储
从mysql4.1开始CHR(n),中N指定的是字符的长度,而不是之前版本的字节长度。也就是说在不同字符集下,CHAR的内部存储不是定长的数据。可以通过select a,char_length(a),length(a) from t;查看字符和字节数。所以在多字符集下,char和varchar占用a空间是一样的。
4.5、innodb数据页结构
InnoDB数据页由七部分组成:File Header:文件头( 38 bytes )Page Header:页头( 56 bytes )Infimum Supremum Records:页中上/下界记录Users Records:用户记录,即行记录Free Space:空闲空间Page Directory:叶目录File Trailer:文件结尾信息
4.6、named file formats
innodb存储引擎通过named file formats机制来解决不同版本下页结构兼容性问题。之前的版本定义为Antelope(包括Compact和Redudant文件格式),最新定义为Barracuda(包括Compressed和Dynamic文件格式)。使用参数innodb_file_format指定文件格式。
4.7、约束
4.7.1、数据完整性
innodb提供了以下四种约束:Primary key,Unique Key,Foreign Key,Default,Not NULL。
4.7.2、约束的创建和查找
创建时候定义,或者使用alter table定义。
4.7.3、约束和索引的区别
primary key和unique key既是约束也是主键。约束是一个逻辑的概念,用来保证数据完整性,而索引是一个数据结构,有逻辑上的概念,在数据库中更是一个物理存储的方式。
4.7.4、对于错误数据的约束
可以通过修改sql_mode来保证约束的强制性。
4.7.5、ENUM和SET约束
由于mysql不支持check约束,所以可以通过ENUM和SET来实现部分需求,还可以通过触发器来实现check约束,注意需要修改sql_mode=’strict_trans_tables’; 只能限于对离散数值的约束,对于ENUM 若插入非法值将插入空字符串作为特殊错误值。
4.7.6、触发器与约束
触发器的作用是在insert,delete和update命令之前或之后自动调用sql命令或者存储过程。所以一个表最多可以建立6个触发器。
4.7.7、外键
4.8、视图
4.8.1、视图的作用
4.8.2、物化视图
Oracle数据库支持物化视图—该视图不是基于基表的虚表,而是根据基表实际存在的实表,物化视图可以用于预先计算并保存表链接或聚集等耗时较多的操作结果。在MS中,这种视图为索引视图。当基表发生了DML操作后,物化视图采用ON DEMAND和ON COMMIT方式刷新进行同步。Mysql的视图不支持物化视图,都是虚拟的。
4.9、分区表
4.9.1、分区表的概述
分区表不是在存储引擎曾完成的,所以不止innodb支持分区表功能。myisma,ndb等都支持。mysql的分区表是水平分区,并不是垂直分区,mysql的分区表是局部分区索引,一个分区中既存储数据又存放索引。当前mysql数据库支持以下几种类型的分区:Range分区,行数据基于属于一个给定连续区间的列值放入分区,这个值只能是整数。VALUE LESS THAN需指定MAXVALUE值的分区,主要用于日期列的分区。对于RANGE分区的查询,优化器只能对YEAR() TO_DAYS() TO_SECONDS()和UNIX_TIMESTAMP()函数进行优化选择。LIST分区和range类似,只是list分区里面是离散的值,这个值只能是整数。(VALUE IN对于未定义的插入,MySQL会抛出异常。对于多条记录同时插入过程中存在未定义的值时,MyISAM分区会允许之前的行数据插入,而拒绝之后的行数据插入,但是InnoDB将其视为一个事务从而ROLLBACK整个插入。HASH分区,根据用户自定义的表达式的返回值 返回值不为负(PARTITION BY HASH (expr) 将数据均匀分布还可按LINEAR HASH分区区别在于算法不同)。hash分区的目的是将数据均匀的分布到预先定义的各个分区中,保证各分区的数据量大致一致。KEY分区,根据mysql数据库提供的哈西函数进行分区。key分区和hash分区相似,不同在于hash分区是用户自定义函数进行分区,key分区使用mysql数据库提供的函数进行分区。columns分区,mysql-5.5开始支持COLUMNS分区,可视为RANGE和LIST分区的进化,COLUMNS分区可以直接使用非整形数据进行分区。RANGE COLUMNS分区可对多个列的值进行分区。不论什么类型的分区,如果表中存在主键和唯一索引,那么分区列必须是主键或者唯一索引的一个组成部分。否则回报错。
4.9.2、子分区
mysql允许在RANGE和LIST分区上再进行HASH或者key的子分区。每个分区上的子分区数量必须相同。在每个分区内,子分区的名称是唯一的,分区可以放到不同磁盘上。
4.9.3、分区中的NULL值
RANGE,HASH,KEY分区如果插入null值,mysql会把它放入最左边的分区,如果删除最左边的分区,null值不会被删除,他会记录到新的最左边的分区。LIST分区如果没有指定NULL值的存放位置,那么就会报错。
4.9.4、分区的性能
OLTP(在线事务处理,如博客,电子商务,网络游戏)系统不适合使用分区表,如果磁盘空间和磁盘IO没出现瓶颈,也不建议使用分区表。而OLAP(在线分析处理,如数据仓库,数据集市)比较适合分区操作。
索引和算法
索引和开销是需要找一个平衡点,过多或者过少都会影响性能,从而导致负载过高,浪费硬件资源。而且索引应该一开始就需要添加上,事后添加的话需要DBA根据监控大量SQL语句,耗费大量时间。
5.1、innodb存储引擎概述
innodb支持常见的两种索引,B 树索引和hash索引。hash索引是自适应的,不能认为干预。B 树是由平衡二叉树演化而来,但是B 树不是一个二叉树。B 树并不能直接找到具体的行,B 树索引只能找到数据行所在的页,然后数据库通过把页读入内存,再在内存中进行查找。
5.2、二分查找法
页中的具体行就是通过二分法查找的。1946年发明的二分查找法,直到1962年才出现完整正确的二分查找法。
5.3、平衡二叉树
平衡二叉树(左节点键值根节点键值 右节点键值)首先的符合二叉树定义,其次必须满足任何节点的左右两个子树高度最大差1.平衡二叉树的效率较高,但是维护平衡二次树需要消耗比较多的资源。多用于内存结构对象中,维护开销相对比较小。
5.4、B 树
B 树是从B树和索引顺序访问方法演化而来。在B 树中,所有记录节点都是按键值的大小顺序存放在同一层的叶节点中,各页节点指针进行链接。同时它们的父节点只是作为索引节点使用。
5.4.1、B 树的插入操作
B 树总会保持平衡,但是对于新插入的值可能需要大量拆分,这样会消耗大量磁盘资源,所以B 树有了旋转(rotation)功能,旋转发生在leat page已经满了,但是其左右节点没有满的情况下,这时B 树并不会着急去拆分页的操作,而且是将记录转移到所在页的兄弟节点上,通常左兄弟先被检查。具体操作看书。
5.4.2、B 树的删除操作
B 树使用填充因子(fill factor)来控制树的删除变化,50%是填充因子可设的最小值。B 树的删除操作同样必须保证删除后页节点中的记录依然排序。具体操作看书。
5.5、B 树索引
B 树索引在数据库中有一个特点是高扇出性(fan out),B 树的高度一般是2-3层。B 树索引可以分为聚集索引(clustered index)和辅助聚集索引(secondary index),其内部都是B 树,叶节点存放着所有的数据。它们不同的是:叶节点存放的是否是一整行的信息。聚集索引:即表中数据按照主键顺序存放,而聚集索引就是按照每张表的主键构造一颗B 树,并且叶节点中存放着整张表的行记录数据。聚集索引的存储并不是物理上的连续,而是逻辑上的连续。它的另一个好处是:对于主键的排序查找和范围查找速度非常快。
辅助索引:也称为非聚集索引,叶级别不包含行的全部数据,叶节点除了包行键值以外,每个叶级别中的索引行中还包含了一个书签,该书签就是对应行数据的聚集索引键。

5.5.1、B 树索引的管理
索引可以索引整个列的数据,也可以只索引一个列的开头部分数据。InnoDB Plugin支持一种称为快速索引创建方法,这种方法只限定于辅助索引,创建索引会对表加上一个S锁,删除时只需将辅助索引的空间标记为可用,并删除内部视图上的对该表的索引定义即可。
5.6、B 树索引的使用
5.6.1、什么时候使用B 树索引
当某个字段的取值范围很广,几乎没有重复,即高选择性,则使用B 树索引是最适合的。根据笔者经验,一般取出数据占整个的20%时,优化器就不会使用索引,而是全表扫描。
5.6.2、顺序读,随机读与预读取
顺序读是指根据索引的叶节点数据就能顺序地读取所需要的行数据,只是逻辑地顺序读在物理磁盘上可能还是随机读取。随机读是指一般需要根据辅助索引叶节点中的主键寻找实际行数据,而辅助索引和主键所在的数据段不同,因此访问方式是随机的。为提高读取性能,InnoDB采用预读取方式将所需数据读入内存,包括随机预读取 random read ahead 和线性预读取 linear read ahead。但是自InnoDB Plugin1.0.4起,随机访问的预读取被取消了,保留了线性预读取,并加入了innodb_read_ahead_threshold参数。它控制一个区中多少页被顺序访问时,InnoDB才启用预读取,预读取下一个页中所有的页。
5.7、hash索引
innodb存储引擎中自适应hash索引使用的是散列表(hash table)的数据结构。但是散列表不只存在于自适应hash中,每个数据库中都存在,用来加速内存中数据的查找。
5.7.1哈西表(hash table)
hash table又叫散列表,由直接寻址表改进而来。利用哈希函数解决了直接寻址遇到的问题,同时又使用链接发解决了碰撞问题。
5.7.2自适应哈西索引
它是数据库系统自己创建并使用的,DBA本身并不能对其进行干预。需要注意的是,哈希索引只能用来搜素等值的查询,对于其它的查找是不能使用哈希索引的。我们只能通过参数innodb_adaptive_hash_index来禁用或启动此特性。
锁
锁是区别文件系统和数据库系统的一个关键特性。
6.1、什么是锁?
锁是用来管理对共享文件的并发访问。innodb会在行级别上对数据库上锁。不过innodb存储引擎会在数据库内部其他多个地方使用锁,从而允许对不同资源提供并发访问。例如操作缓冲池中的LRU列表,删除,添加,移动LRU列表中的元素,为了保证一致性,必须有锁的介入。
6.2、innodb存储引擎中的锁
6.2.1、锁的类型
S lock 共享锁允许事务读一行数据。X lock 排它锁允许事务删除或者更新一条数据。IS lock 意向共享锁事务想要获得一个表中某几行的共享锁。IX lock 意向拍他所事务想要获得一个表中某几行的排它锁。因为InnoDB存储引擎支持的是行级别的锁,所以意向锁其实不会阻塞除全表扫描以外的任何请求。
6.2.2、一致性的非锁定读操作
一致性非锁定读(consistent nonlocking read)是指innodb通过多版本控制(multi versioning)的方式来读取当前执行时间数据库中行的数据。非锁定读的机制大大提高了数据读取的并发性,在InnoDB引擎中为默认的读取方法,即读取不会占用和等代表上的锁。多版本控制是通过快照实现的,快照数据其实就是当前数据之前的历史版本,可能有多个版本。这种技术称为行多版本技术,由此带来的并发控制叫做多半本并发控制(multi version concurrency control,MVCC).在Read Committed和Repeatable Read(innodb默认的事务隔离级别)下,innodb存储引擎使用非锁定的一致性读。但是对于快照数据的定义却不同。在Read Commited级别,对于快照数据,非一致性读总是读取被锁定行的最新一份快照。在Repeatable级别下,对于快照数据,非一致性读总是读取事务开始时的行数据版本。
6.2.3、SELECT…FOR UPDATE &SELECT…LOCK IN SHARE MODE
SELECT…FOR UPDATE 可以获得一个X锁。SELECT…LOCK IN SHARE MODE 可以获得一个S锁。注意上述操作时必须使用显示提交方式,即加上begin,start transaction或者set autocommit = 0。
6.2.4、自增长和锁
对于含有子增长计数器的表进行插入时,会执行”SELECT MAX(auto_inc_col) FROM t FOR UPDATE;”插入操作会更具这个自增长的计数器值加1赋予自增长列。这个实现方式叫做AUTO-INC Locking。这是一种特殊的锁,为了提高并发,它不会在事务执行完才释放,只是在语句执行后立即释放。从mysql-5.1.22版本开始,innodb引擎提供了一种轻量级互斥量的自增长实现机制,这种机制大大提高了子增长值插入的性能。并且mysql-5.1.22开始,innodb引擎提供了一个参数innodb_autoinc_lock_mode,默认的值为1。在讨论新的增长方式之前我们需要对自增长实现方式分类:1.INSERT-LIKE:指所有的插入语句,比如 INSERT、REPLACE、INSERT…SELECT、REPLACE…SELECT,LOAD DATA等。2.Simple insert:指在插入前就能确定插入行数的语句,包括INSERT、REPLACE,不包含INSERT…ON DUPLICATE KEY UPDATE这类语句。3.Bulk inserts:指在插入前不能确定得到插入行的语句。如INSERT…SELECT,REPLACE…SELECT,LOAD DATA.4.Mixed-mode inserts:指其中一部分是子增长的,有一部分是确定的。现在有SIMPLE INSERT、BULK INSERTS、MIXED-MODE INSERTS三种类型的INSERT语句,有AUTO-inc locking(最早的)和轻量级互斥量的自增长两种auto—increment锁。1.innodb_autoinc_lock_mode=0 5.1.22之前的方式,也就是所有类型的insert都用AUTO-inc locking。2.innodb_autoinc_lock_mode=1 这个参数是5.1.22之后出现的也是之后的默认值,对于SIMPLE INSERT,使用轻量级互斥量的锁,对于BULK INSERT,使用AUTO-inc locking。3.innodb_autoinc_lock_mode=2 指不管什么情况都使用轻量级互斥的锁,效率最高,但是复制只能使用row-basereplication,因为statement-base replication会出现问题。另外就是innodb和myisam的一个区别,innodb下,自增长必须是索引,而且必须是索引的第一个列,不然会报错,myisam不会出现这个问题。
6.2.5、外键和锁
外键主要用于引用完整性的约束检查。innodb中,对于一个外键列,如果没有显示的对这个列加索引,innodb就自动的对其加一个索引。
6.3、锁的算法
1.Record Lock,单行记录上的锁,锁住索引记录。2.GapLock,间隙锁能锁定一个范围,但不包括记录本身如 6 时,依然可以插入6。3.Next-KeyLock:Gap Lock Record Lock,锁定一个范围并且锁定记录本身,如 6,插入6时会被阻塞。在REPEATABLE READ模式下 Next-KeyLock算法是默认的行记录锁定算法。
6.4、锁问题
本来锁问题会导致的是更新丢失、幻读、脏读、不可重复读,但是innodb作者却只写出了三种问题,可能是幻读通过innodb Next-key Lock解决了,作者就没有提及。这几个锁问题对应事务隔离的4个安全级别:READ UNCOMMITTED(事务隔离最低的级别,有事务隔离就能解决更新丢失,但是存在脏读的问题)。READ COMMITED(ORACLE和SQL SERVER默认的隔离级别,解决了脏读,但是一个事务多次读取的内容不同,出现了不可重复读的问题)。READ REPEATABLE(可重复读,innodb引擎的默认事务隔离级别,解决了不可重复读的问题,但是产生了幻读,innodb通过Next-key lock解决了幻读)。SERIALIZABLE(可串行话,通过强制事务排序解决幻读问题,会降低性能)总的看来innodb默认的 READ REPEATABLE是非常棒的。
6.5、阻塞
innodb中需要其他事务的锁释放它锁占用的资源,这个时候就会发生锁等待,这就是阻塞。innodb引擎有两个相关参数:innodb_lock_wait_timeout 用来设定等待的时间,默认是50秒,这是一个动态参数,可以随时调整;innodb_rollback_on_timeout用来设定是否在等待超时时对进行中的事务进行回滚操作,默认是OFF,代表不回滚,这是一个静态参数。
6.6、死锁
死锁会产生阻塞,所以可以通过6.5的参数,让超时的阻塞回滚。还有就是开发的时候,每个事务对表,字段,行的操作,都是顺序的,这样可以很大程度上避免死锁。
以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
标签: MYSQL
相关文章
- 详细阅读
- 详细阅读
-
如何处理'mysql' 不是内部或外部命令的报错详细阅读
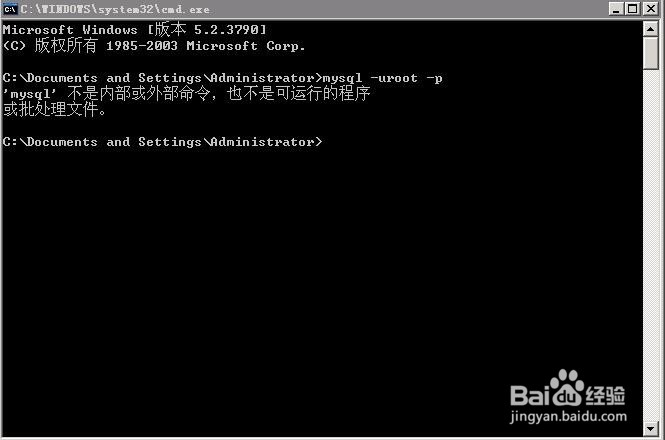
如何处理mysql 不是内部或外部命令的报错,今天安装myql-5.7.23,想要从命令行中连接myql,结果出现如图报错。下面来写下,这种报错的解决方式:......
2023-03-16 500 MYSQL
