如何更改Django默认主页为自定义主页,更改Djago默认主页为自定义主页,这是开始网页的第一步。......
Python爬取时如何判断HTML标签
来源:互联网
2023-03-16 19:06:49 339
Python爬取时对html标签进行判断
工具/原料
- Python 3.6及以上环境
方法/步骤
首先获取到html的源代码,示例如下:
import requests
response = requests.get(url).text
此时response就是这个url的html源代码。

得到源代码之后就要判断html的标签了。
可以直接判断:
if 'baidu' in response:
print('baidu 这个字符串在源代码里')
else:
print('baidu 这个字符串不在源代码里')
当然这种情况适合要判断的html比较固定,比如就是‘baidu’这个字符串,或者其他固定不变的字符串都是可以的。
那如果字符串是变化的怎么办呢?往下看。
如果要判断的html标签是变化的,需要找到变化的规律,然后用正则表达式来判断即可。
比如图片中的一截代码,如果id='2'中的2是变化的,可能是3可能是5等。
import re
if re.search("id='(\d )'",response).group():
print('html标签中包含id')
else:
print('html标签中不包含id')
这样就可以灵活判断html的标签了。

以上两种方法可以简单的判断html的标签,正则表达式在实际使用中要灵活使用。
注意事项
- 注意浏览器看到的源代码和Python获取的源代码是否相同
以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
相关文章
- 详细阅读
-
python中关于单/双引号和转义引号的区别详细阅读
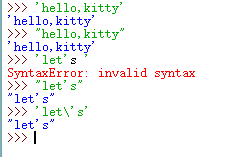
python中关于单/双引号和转义引号的区别,ytho中单/双引号的作用是将引号中间的符号以字符串的形式传递,而在ytho中它们两个的功能是一样的,只不过在遇到转义引号的时候,两者的使用才有所区别,现......
2023-03-16 323 python
- 详细阅读