如何更改Django默认主页为自定义主页,更改Djago默认主页为自定义主页,这是开始网页的第一步。......
python下用pandas实现数据统计--groupby分组
来源:互联网
2023-03-16 19:13:37 295
在使用pandas时,数据统计的分组计算,比如:求平均 求和 求中值 求方差等非常常用,pandas提供了强大的分组函数 groupby可以轻松地完成这个工作。
本文介绍 单列分组,两列分组 , 求和 求平均 和describe 时间分组还有筛选 ,六个例子。
工具/原料
- pycharm win7环境
- pandas python3
方法/步骤
groupby广泛用在数据统计之中,可以实现很多数据库函数的功能。
本文仅从单列分组,两列分组 , 求和 求平均 和 describe 时间分组还有筛选 ,六个方面例子进行说明。
数据初始化代码:
import pandas as pd
import numpy as np
import os
import sys
exampleData = {'电源': ['220v', '110v', '28v', '5v', '3v'],
'电阻': ['100', '100', '100', '1M', '2.2K'],
'厂家': ['A厂', 'B厂', 'A厂', 'B厂', 'C厂' ],
'数量': [5, 20, 14, 15, 20]}
df = pd.DataFrame(exampleData)
print(df)


#按厂家分组,并统计个数
print("------数据分组统计个数-----")
groupnum = df.groupby(['厂家']).size()
print(groupnum)
#打印每组数据 这个很有用
print("------数据分组-----")
for groupname,grouplist in df.groupby('厂家'):
print(groupname)
print(grouplist)

# 求平均#将数量转换成浮点型,然后分组求均值print("------数据分组求平均-----")groupmean = df['数量'].astype(float).groupby(df['厂家']).mean()print(groupmean, type(groupmean))# 求和#将数量转换成浮点型,然后分组求和print("------数据分组求和-----")groupsum = df['数量'].astype(float).groupby(df['厂家']).sum()print(groupsum, type(groupsum))

#追加列
print("------追加列-----")
df['地点'] = ['上海','北京',"大陆",'台湾','广州']
df['日期'] = ['2019-03-11','2019-03-16',"2019-03-16",'2019-03-16','2019-03-15']
print(df)
print("------多 列 数据分组统计个数-----")
groupnum = df.groupby(['厂家','电阻']).size()
print(groupnum)

# 按厂家与电阻分组,求数量这一列均值
print("------按厂家与电阻分组,求数量这一列均值--")
groupmean = df['数量'].astype(float).groupby([df['厂家'],df['电阻']]).mean()
print(groupmean)
# 按厂家与电阻分组,求数量这一列sum
print("------按厂家与电阻分组,求数量这一列sum--")
groupsum = df['数量'].astype(float).groupby([df['厂家'],df['电阻']]).sum()
print(groupsum)
print("------按厂家与电阻分组,求数量这一列describe--")
groupdescribe = df['数量'].astype(float).groupby([df['厂家'],df['电阻']]).describe()
print(groupdescribe)

print("------按厂家 分组,日期这一列count--")
# 转化为时间格式
df["新日期"] = pd.to_datetime(df["日期"],format ="%Y-%m-%d")
print(df)
groupcount = df.groupby([df['新日期']]).count()
print(groupcount)
groupnum = df.groupby(['新日期']).size()
print(groupnum)
# 按照年分组
print(df.groupby(df["新日期"].apply(lambda i:i.year)).count())

# 到这里是按月分组
new_df = df.groupby(df["新日期"].apply(lambda i:i.day),as_index=False)
print(new_df)
print("------数据分组-----")
for groupname,grouplist in new_df:
print(groupname)
print(grouplist)
#打印按天 并且筛选数据只有一个的
newdf = df.groupby(df["新日期"].apply(lambda i:i.day),as_index=False).filter(lambda i: len(i)==1)
print(newdf)
#打印按天 并且筛选数据大于一个的
newdf = df.groupby(df["新日期"].apply(lambda i:i.day),as_index=False).filter(lambda i: len(i) > 1)
print(newdf)

注意事项
- groupby 可以和lambda 配合使用
- 注意 filter 的使用
以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
标签: python
相关文章
- 详细阅读
-
python中关于单/双引号和转义引号的区别详细阅读
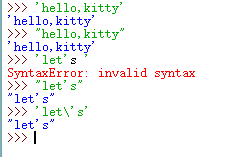
python中关于单/双引号和转义引号的区别,ytho中单/双引号的作用是将引号中间的符号以字符串的形式传递,而在ytho中它们两个的功能是一样的,只不过在遇到转义引号的时候,两者的使用才有所区别,现......
2023-03-16 353 python
- 详细阅读