如何更改Django默认主页为自定义主页,更改Djago默认主页为自定义主页,这是开始网页的第一步。......
requests得到的怎么转换成html
来源:互联网
2023-03-16 19:16:58 340
requests得到的怎么转换成html,requests是python里的第三方库,经常用于爬虫方面,在python3中,requests可以和bs4进行很好的配合获取html内容,这里就给大家介绍一下用法吧。

工具/原料
- python3.7
- sublime text3
方法/步骤
这里用sublime text 3 作为示范,首先要创建一个py文档。

import requests
第一步要引入模块,这是第三方库,如果没有安装需要用pip install requests来安装。

result = requests.get("网页地址")
这里我们首先要用一个变量存储获取到的网页,方便进行下一步的操作。

result.raise_for_status()
加上这一句,防止如果网页打不开的情况,比如404。

print(result)
这里打印变量,可以看到是200,这就是可以正确访问网页,并且可以存储。

import requests, bs4
soup = bs4.BeautifulSoup(result.text, 'lxml')
再引入一个第三方库bs4,然后进行网页解析。
这个时候打印一下就能得到html了。

注意事项
- 如果出现乱码要转化为utf-8
以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
上一篇:Python用户密码解锁小程序 下一篇:Python审问罪犯小游戏
相关文章
- 详细阅读
-
python中关于单/双引号和转义引号的区别详细阅读
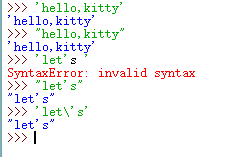
python中关于单/双引号和转义引号的区别,ytho中单/双引号的作用是将引号中间的符号以字符串的形式传递,而在ytho中它们两个的功能是一样的,只不过在遇到转义引号的时候,两者的使用才有所区别,现......
2023-03-16 353 python
- 详细阅读