如何更改Django默认主页为自定义主页,更改Djago默认主页为自定义主页,这是开始网页的第一步。......
Python爬取时如何判断HTML标签
来源:互联网
2023-03-16 19:17:36 版权归原作者所有,如有侵权,请联系我们
Python爬取时如何判断HTML标签。python语言在爬虫方面有着强大的功能,当然需要配合第三方库来进行执行,爬取到的信息也可以是多种多样的,那么网页是由HTML编写结构的,python是可以轻松判断出HTML标签的。

工具/原料
- windows7
- sublime text3
- chrome浏览器
方法/步骤
首先我们打开编辑器,然后新建一个py后缀的文件,这是一个PYTHON的文件。

from bs4 import BeautifulSoup
import requests
首先要引入这两个库,这是要爬虫的非常常见的库,等会会展现他们的功能。

website = "网页"
result = requests.get(website)
result.encoding = "utf-8"
content = result.text
print(content)
这里我们就可以用requests这个库来先获取整个网页的HTML代码。并且打印一下查看是否有问题。

soup = BeautifulSoup(content, "html.parser")
print(soup)
接着就是用BeautifulSoup来解析一下内容,并且保存在变量里面。

现在可以来判断和获取HTML标签了,HTML标签是由>/>这样的格式组成的。
title_tag = soup.title
print(title_tag)
print(title_tag.text)
比如我们看到了title标签想获取,就可以指定名字即可,如果要里面的内容可以用text。

但是往往标签都是有多个的,我们需要用find_all()来把所有给找出来。
div_tag = soup.find_all("div")
print(div_tag)
然后PYTHON会存储在列表里面。

注意事项
- pip install可以安装第三方库
以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
相关文章
- 详细阅读
-
python中关于单/双引号和转义引号的区别详细阅读
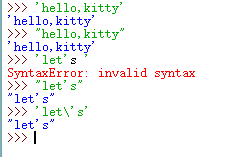
python中关于单/双引号和转义引号的区别,ytho中单/双引号的作用是将引号中间的符号以字符串的形式传递,而在ytho中它们两个的功能是一样的,只不过在遇到转义引号的时候,两者的使用才有所区别,现......
2023-03-16 353 python
- 详细阅读