如何更改Django默认主页为自定义主页,更改Djago默认主页为自定义主页,这是开始网页的第一步。......
Python爬取时如何判断HTML标签
来源:互联网
2023-03-16 19:21:23 版权归原作者所有,如有侵权,请联系我们
在Python语言中,可以使用第三方包requests请求网站网页标签和数据,然后使用BeautifulSoup解析HTML标签。那么,Python爬取时如何判断HTML标签?

工具/原料
- Python
- pycharm
- 截图工具
- WPS
方法/步骤
打开pycharm工具,新建Python文件;在文件中,依次导入requests和BeautifulSoup

查找一个网站地址,然后赋值给变量url,作为解析数据和标签的来源

调用requests.get()方法获取网站的数据,并设置编码格式为utf-8

获取请求成功后的text属性,赋值给变量cte并打印值

保存代码并运行Python文件,可以查看到控制台打印一些HTML标签和数据

调用BeautifulSoup中的方法对HTML进行解析,然后使用find_all()方法查找label标签

再次保存代码并运行Python文件,可以查找到所有label标签元素和对应的数据

总结
1、安装requests和BeautifulSoup
2、打开工具并新建Python文件
3、导入requests和BeautifulSoup
4、调用requests.get()获取数据
5、调用BeautifulSoup解析HTML
6、调用find_all方法查找label标签
7、保存代码并运行文件查看结果

注意事项
- 注意Python爬取时如何判断HTML标签
- 注意Python语言如何解析HTML标签
以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
上一篇:python怎样获取前台数据 下一篇:python怎么画一个红色三角形
相关文章
- 详细阅读
-
python中关于单/双引号和转义引号的区别详细阅读
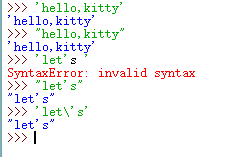
python中关于单/双引号和转义引号的区别,ytho中单/双引号的作用是将引号中间的符号以字符串的形式传递,而在ytho中它们两个的功能是一样的,只不过在遇到转义引号的时候,两者的使用才有所区别,现......
2023-03-16 351 python
- 详细阅读